python爬虫项目
MTG卡片价格爬取
cninfo信息爬取
汽车之家数据爬取
5秒克隆你的声音-Real-Time-Voice-Cloning项目学习
js逆向案例-dy之X-Bogus/signature算法分析【转】
pyinstaller打包exe免杀和逆向浅析
【实用】从一个exe到pyc文件的实操-逆向
B站直播弹幕协议详解
快手API发布作品
Tiktok直播间弹幕获取
spider之字体css解密和RSA解密
requests报错问题
Requests被网站识别咋办?使用curl_cffi,支持原生模拟浏览器TLS/JA3指纹的 Python 库
【实用技巧】使用Byteasy进行手抓
本文档使用 MrDoc 发布
-
+
up
down
首页
spider之字体css解密和RSA解密
目标网址: https://ksanquan.aqscpx.com/ 网址为一个考试试题学习网,帐号密码是用户提供,且有学习卡订阅了几个学习的。 ## 网址内容解析  看到题目和试题解析是经过RSA加密的,只不过是浏览器再解密后呈现出来后面的内容。 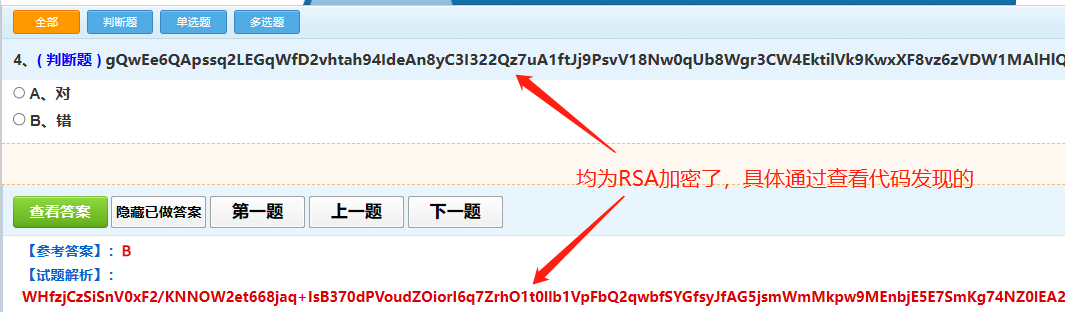 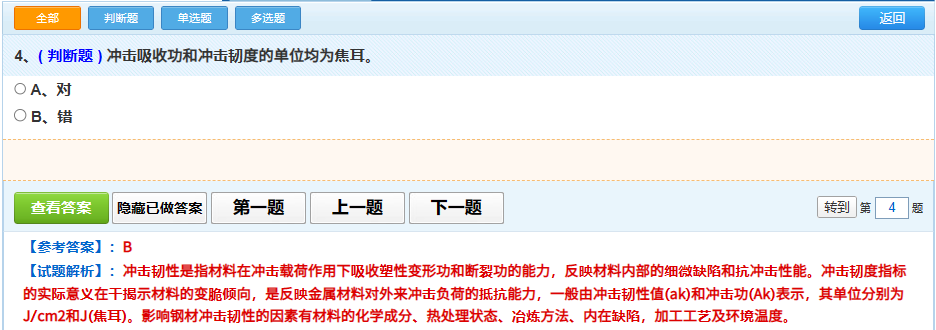 分析该请求的响应结果,看到获取的是html内容,题目和试题解析是加密后的字符串,参考答案是加密后的,实体选项是未加密的,如下: 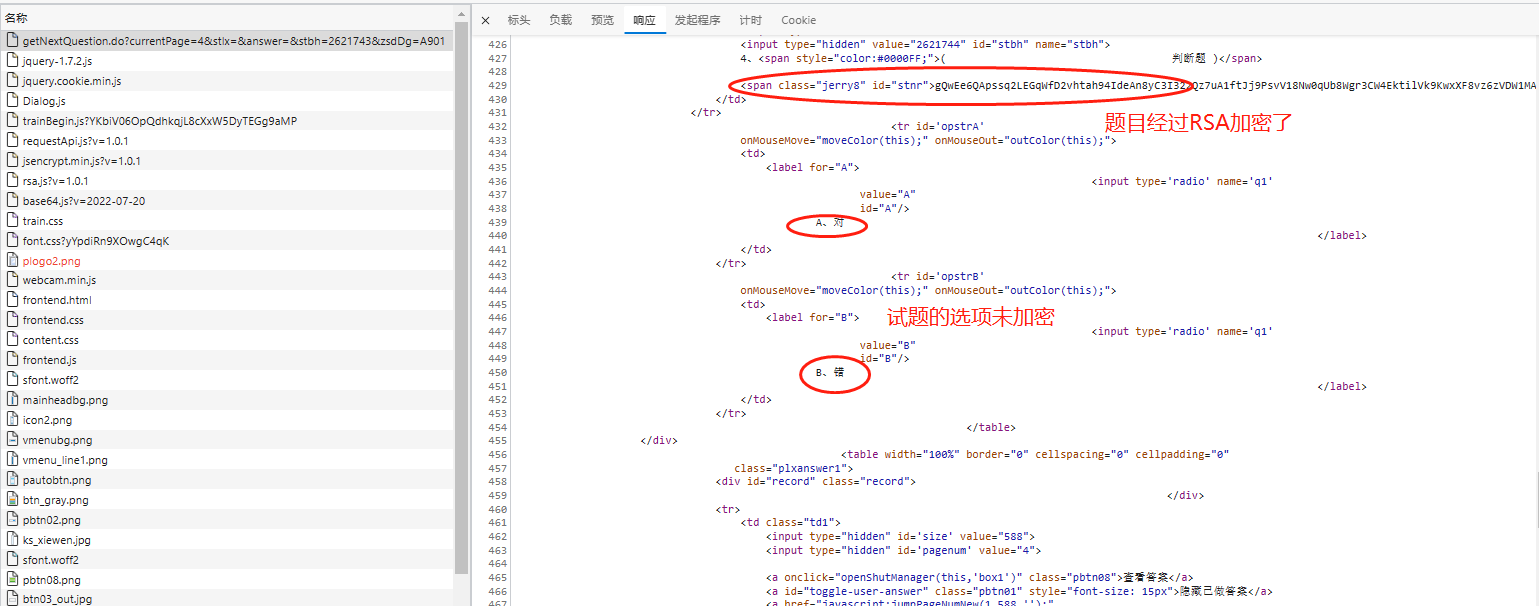 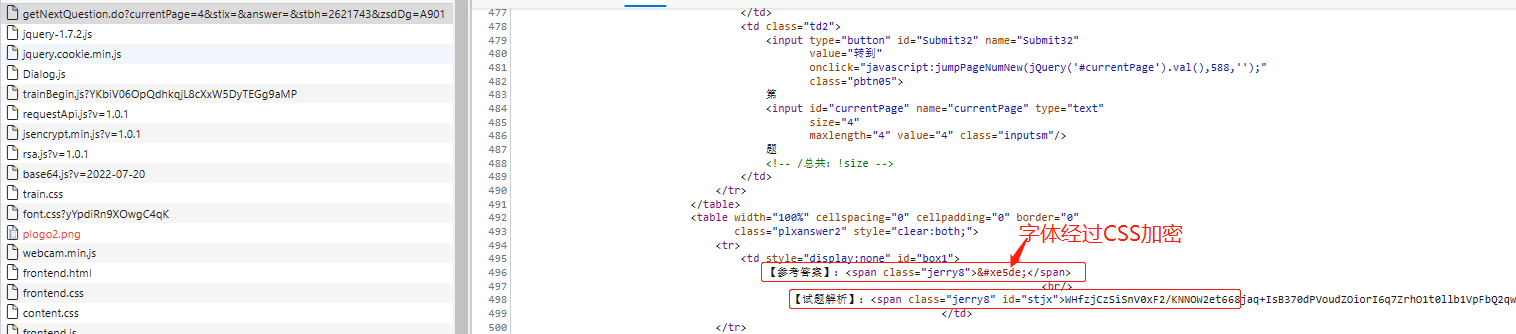 ## 构建请求 点击下一题或上一题后,提示一个请求是`https://ksanquan.aqscpx.com/user/4536131/getNextQuestion.do?currentPage=587&stlx=&answer=&stbh=8200106&zsdDg=A901` 对该请求点右键进行复制其curl,提交到网址https://curlconverter.com/python/ 上面进行解析: **解析前** ``` curl 'https://ksanquan.aqscpx.com/user/3965338/getNextQuestion.do?currentPage=788&stlx=&answer=&stbh=4221931&zsdDg=AA02' \ -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \ -H 'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \ -H 'Connection: keep-alive' \ -H 'Cookie: SESSION=c3fb56ac-379f-49ec-8145-142a00956261; jerry-uid=13686267636; jerry-pwd=123456; jerry-isRemember=1; knowledgePc_4536131_A901=588; knowledgePc_4536132_A804=1011; knowledgePc_3732935_A803=558; knowledgePc_3913246_AA01=949; knowledgePc_3965338_AA02=788' \ -H 'Referer: https://ksanquan.aqscpx.com/user/3965338/getCurrentQuestion.do?currNum=789&zsdDg=AA02' \ -H 'Sec-Fetch-Dest: document' \ -H 'Sec-Fetch-Mode: navigate' \ -H 'Sec-Fetch-Site: same-origin' \ -H 'Sec-Fetch-User: ?1' \ -H 'Upgrade-Insecure-Requests: 1' \ -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70' \ -H 'sec-ch-ua: "Not_A Brand";v="99", "Microsoft Edge";v="109", "Chromium";v="109"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "Windows"' \ --compressed ``` **解析后** ``` import requests cookies = { 'SESSION': 'c3fb56ac-379f-49ec-8145-142a00956261', 'jerry-uid': '13686267636', 'jerry-pwd': '123456', 'jerry-isRemember': '1', 'knowledgePc_4536131_A901': '588', 'knowledgePc_4536132_A804': '1011', 'knowledgePc_3732935_A803': '558', 'knowledgePc_3913246_AA01': '949', 'knowledgePc_3965338_AA02': '788', } headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', # 'Cookie': 'SESSION=c3fb56ac-379f-49ec-8145-142a00956261; jerry-uid=13686267636; jerry-pwd=123456; jerry-isRemember=1; knowledgePc_4536131_A901=588; knowledgePc_4536132_A804=1011; knowledgePc_3732935_A803=558; knowledgePc_3913246_AA01=949; knowledgePc_3965338_AA02=788', 'Referer': 'https://ksanquan.aqscpx.com/user/3965338/getCurrentQuestion.do?currNum=789&zsdDg=AA02', 'Sec-Fetch-Dest': 'document', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-User': '?1', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70', 'sec-ch-ua': '"Not_A Brand";v="99", "Microsoft Edge";v="109", "Chromium";v="109"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } params = { 'currentPage': '788', 'stlx': '', 'answer': '', 'stbh': '4221931', 'zsdDg': 'AA02', } response = requests.get( 'https://ksanquan.aqscpx.com/user/3965338/getNextQuestion.do', params=params, cookies=cookies, headers=headers, ) ``` 从解析后中看到,提交需要有参数params中: - `currentPage` 设置第几题 - `stlx` 试题类型,为空表示全部 - `stbh` 是每个大类科目不同的 - `zsdDg` 是每个大类科目的代码,订阅的就固定的几类:A803/A804/A901/AA01/AA02 ## RSA解密 搜索题目和试题解析的id值,发现在该请求的响应结果html代码中有如下内容: ``` window.onload=function () { var tmnr = jQuery("#stnr").text(); tmnr = b64tohex(tmnr) tmnr = encrypt.decryptLong(tmnr) jQuery("#stnr").html(fixQuestionContent(tmnr)) var stjx = jQuery("#stjx").text(); stjx = b64tohex(stjx) stjx = encrypt.decryptLong(stjx) jQuery("#stjx").html(stjx) } ``` 可以看出,该内容在界面加载后就会执行b64tohex,encrypt.decryptLong等函数,他们均是对试题字符串进行了解密的。 和加密解密相关的函数均在 `jsencrypt.min.js`, `rsa.js`, `base64.js`中(可见为RSA加密方法),构建js文件: ``` # 复制三个js文件内容进来 # 最后添加一个函数,就是上面window.onload的内容中的几句话 function decode(data) { var tmnr = b64tohex(data) tmnr = encrypt.decryptLong(tmnr) return tmnr } ``` 由此,在py代码中调用该js,代码如下: ``` #====================================================== ''' 下面这部分代码是防止windows中报decode之类的错''' import subprocess # 创建一个新的 Popen 类,并继承自 subprocess.Popen class MySubprocessPopen(subprocess.Popen): def __init__(self, *args, **kwargs): # 在调用父类(即 subprocess.Popen)的构造方法时,将 encoding 参数直接置为 UTF-8 编码格式 super().__init__(encoding='UTF-8', *args, **kwargs) # 必须要在导入 PyExecJS 模块前,就将 subprocess.Popen 类重置为新的类 subprocess.Popen = MySubprocessPopen #====================================================== import execjs with open("RSAdecode.js", "r", encoding="utf-8") as f: jscode = f.read() ctx = execjs.compile(jscode) #res = ctx.call("decode", "cK21nhxsaprOFJtX2llxxu/Tm0yvRVrnymzmV9RKHVuMWXYqR+oHd+c1ASP/KWp6uiw6ynYH4+H6c5k0TbbH4QCv1e56lDcMuz4tI1C2NkUyEkUF6+8YwcOK0GkgoN0CuBp3sb97rI2zYa2mWYKeZp8aearOmLHaZtby+rszOPc=") #print(res);exit() ``` ## CSS字体解密 通过搜索他们class(如上图均为jerry8),发现font.css中有对应的11个字体文件。发现加密方法是css字体加密,fiddle抓取发现字体文件是woff2,因此是通过该字体进行css加密。 且Fiddle中发现,该`class='jerry8'`对应的font文件是 https://file.tskspx.cn/webfile/jerry-script/font-files/webFont/font9/sfont.woff2 ,下载该woff2字体文件。 通过[fonteditor网站](https://kekee000.github.io/fonteditor/) 打开,如下: 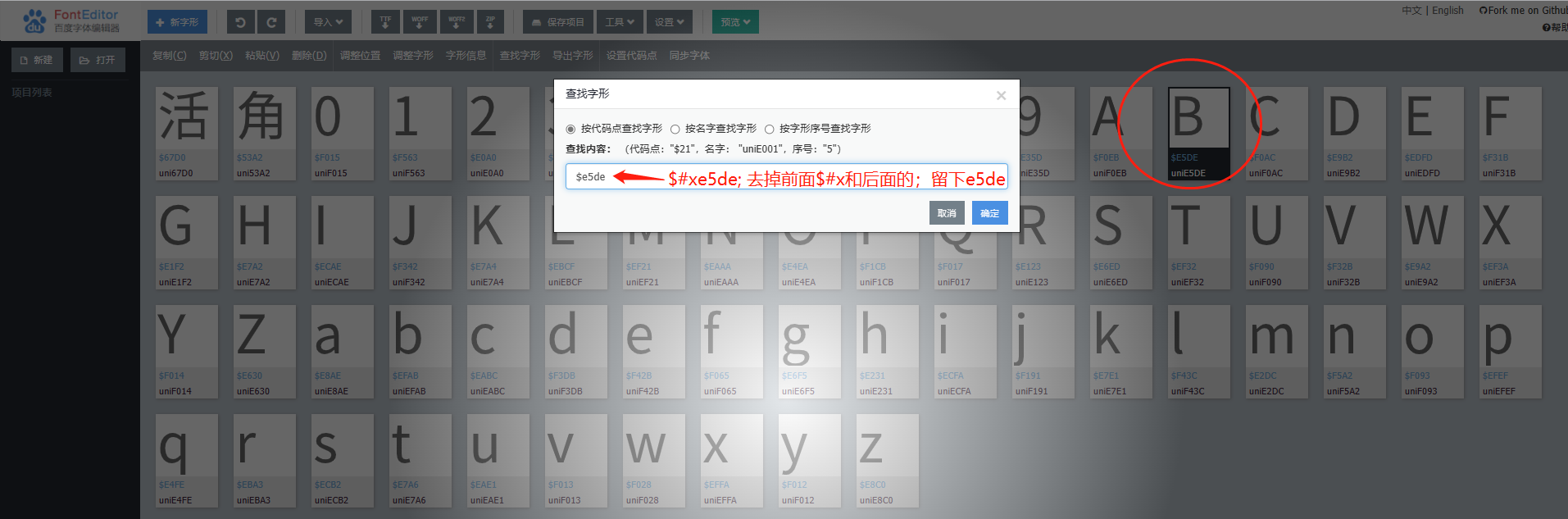 查看到了,该案例解析出就是B字母,在进行反复刷新,查看是否是动态字体。反复刷新后,网页变动的是class的值,对应到其他font文件,如果相同的class值该字符串是相同的。**因此,该网站只采用了静态字体加密,只不过是进行了动态改变class的值**。 **解密方法:** 1. 首先做好字体映射关系 通过截图fonteditor网站上的映射关系,然后直接微信识别复制(这儿可以改成OCR识别,但是字体svg经常会识别错误,需要找更高精度的识别)。 发现所有都是一样的顺序,只不过是每个字下面对应的编码不同而已。因此只要一个该值即可: ``` jerryFonts = {"jerry9":"""的设用应安全备定种电特规动作压是机 行在不时装力有人和器气使检于位车管为 度可理重要中以制大当一员单梯或起置下 工容式验能监炉水进运业对施体法接上锅 门量生事部过内故保发道程分关件瓶其等 高合与热方证后质充查 .... """ ``` 2. 读取font文件中每个字的编码 ``` fontFile = "fonts/{}.woff2".format(jerryNum) jfont = re.sub(r"\s+", "", jerryFonts["jerry9"]) # 映射出来的每个字,所有字都相同,就是编码不同 font = TTFont(fontFile) uni_list = font.getGlyphOrder()[1:] utf8List = ['&#x' + uni[3:] for uni in uni_list] #获得编码顺序 ``` ## 主程序代码 ``` import time, random import requests from bs4 import BeautifulSoup cookies = { 'SESSION': 'c3fb56ac-379f-49ec-8145-142a00956261', 'jerry-uid': '13686267636', 'jerry-pwd': '123456', 'jerry-isRemember': '1', 'knowledgePc_4536131_A901': '1', } def getOneQuestion(number, stbh, zsdDg): headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', # 'Cookie': 'JSESSIONID=3EF10E3BEEB995CBB916E28E0650D460; jerry-uid=13686267636; jerry-pwd=123456; jerry-isRemember=1; knowledgePc_3965338_AA02=1; SESSION=8e802f1d-ace2-4f78-b1bb-7e0f3405826d; knowledgePc_3732935_A803=1', 'Referer': 'https://ksanquan.aqscpx.com/user/3732935/getNextQuestion.do?currentPage={}&stlx=&&zsdDg={}'.format(number, zsdDg), 'Sec-Fetch-Dest': 'document', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-User': '?1', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70', 'sec-ch-ua': '"Not_A Brand";v="99", "Microsoft Edge";v="109", "Chromium";v="109"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } params = { 'currentPage': str(number), 'stlx': '', 'answer': '', 'stbh': str(stbh), # 2624479/2625177/2621741/2623441/2622467 'zsdDg': zsdDg, # A803/A804/A901/AA01/AA02 } response = requests.get( 'https://ksanquan.aqscpx.com/user/3965338/getNextQuestion.do', params=params, cookies=cookies, headers=headers, ) return response from fontTools.ttLib import TTFont import matplotlib.pyplot as plt import re from jerry2font import jerryFonts from zhon.hanzi import punctuation as punc1 from string import punctuation as punc2 punctuation = punc1 + punc2 punctuation = list(punctuation) def jerryStr2font(jerryNum, strA): fontFile = "fonts/{}.woff2".format(jerryNum) jfont = re.sub(r"\s+", "", jerryFonts["jerry9"]) # 所有都相同,就是编码不同 font = TTFont(fontFile) uni_list = font.getGlyphOrder()[1:] utf8List = ['&#x' + uni[3:] for uni in uni_list] #print(uni_list);print(utf8List);print(jfont) def transl(strA): output = "" for i in strA.split(";"): i = i.strip() pre = "" while True: if i and (re.findall(r'[\u4e00-\u9fa5]', i[0]) or re.findall(r'[^A-Za-z0-9&#;]', i[0])): pre += i[0] i = i[1:] else: break output += pre if i: i = i.strip(";").strip("&#x") i = i.upper() i = "&#x" + i i = re.sub(r"\\u", "", i) output += jfont[utf8List.index(i)] return output output = "" if "()" in strA: idx = strA.index("()") strA1 = strA[:idx] strA2 = strA[idx+2:] output = transl(strA1) + "()" + transl(strA2) else: output = transl(strA) return output def cssFontDecode(fontFile, strA): font = TTFont(fontFile) strA = strA.strip(";").strip("&#x") strA = strA.upper() coor = font["glyf"]["uni"+strA].coordinates coor = list(coor) fig, ax = plt.subplots() x = [i[0] for i in coor] y = [i[1] for i in coor] plt.fill(x, y, color="k", alpha=1) for key,spine in ax.spines.items(): if key in ["right", "top", "bottom", "left"]: spine.set_visible(False) plt.plot(x,y) plt.axis("off") plt.savefig("uni"+strA+".png") #plt.show() return "uni"+strA+".png" try: from PIL import Image except: import Image import pytesseract def OCR(imgFile): captcha = Image.open(imgFile) print(captcha) result = pytesseract.image_to_string(captcha, lang="chi_sim", config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789').strip() print(result) # Press the green button in the gutter to run the script. if __name__ == '__main__': # imgFile = cssFontDecode("fonts/jerry2.woff2", "") # OCR(imgFile) # font = TTFont("fonts/jerry2.woff") # font.saveXML("fonts/jerry2.xml") # test #a = '配需引壁到型温修()罚荷选计' #a = "足缆油置定活者壁反油置足缆。此题改害" #print(jerryStr2font("jerry5", a)); exit() import subprocess # 创建一个新的 Popen 类,并继承自 subprocess.Popen class MySubprocessPopen(subprocess.Popen): def __init__(self, *args, **kwargs): # 在调用父类(即 subprocess.Popen)的构造方法时,将 encoding 参数直接置为 UTF-8 编码格式 super().__init__(encoding='UTF-8', *args, **kwargs) # 必须要在导入 PyExecJS 模块前,就将 subprocess.Popen 类重置为新的类 subprocess.Popen = MySubprocessPopen import execjs with open("RSAdecode.js", "r", encoding="utf-8") as f: jscode = f.read() ctx = execjs.compile(jscode) #res = ctx.call("decode", "cK21nhxsaprOFJtX2llxxu/Tm0yvRVrnymzmV9RKHVuMWXYqR+oHd+c1ASP/KWp6uiw6ynYH4+H6c5k0TbbH4QCv1e56lDcMuz4tI1C2NkUyEkUF6+8YwcOK0GkgoN0CuBp3sb97rI2zYa2mWYKeZp8aearOmLHaZtby+rszOPc=") #print(res);exit() stbhs = '2624479/2625177/2621741/2623441/2622467'.split("/") zsdDgs = 'A803/A804/A901/AA01/AA02'.split("/") #import openpyxl #wb = openpyxl.Workbook() # 创建Workbook()对象 #ws = wb.active #sheet = wb['Sheet'] # 通过名称获取工作薄 outfile = open("part2gaochu.tsv", "a+") start = 169; end = 950 for ii in range(start, end): res = getOneQuestion(ii, '8204812', 'AA01') #res.encoding = 'utf-8' soup = BeautifulSoup(res.content, "html.parser",from_encoding="utf-8") print("[INFO] 抓取第{}题".format(ii)) bodys = soup.find_all("body") if len(bodys) != 2: print("ERROR: cookie过期了吧!"); exit() else: table1 = bodys[1].find(attrs={'class':'ks_st'}) trs = table1.find_all("tr") # 题目 titleSpan = trs[0].find(attrs={'id':'stnr'}) className = titleSpan.attrs["class"][0] #print(titleSpan) title = re.sub(r"\s+", "", trs[0].text) parts = title.split(")") title = parts[0]+")" title2Codes = ctx.call("decode", parts[1]) title2 = jerryStr2font(className, title2Codes) # 每个选项 selects = [] for tr in trs[1:]: select1 = re.sub(r"\s+", "", tr.text) selects.append(select1) selects = "|".join(selects) print(selects) table2 = bodys[1].find(attrs={'class':'plxanswer2'}) spans = table2.tr.td.find_all("span") #print(table2.tr.td.find("span")) if len(spans) == 1: className = spans[0].attrs["class"][0] anwser = spans[0].text anwser = anwser.encode('raw_unicode_escape').decode('utf-8').replace('\\u', '') anwser = jerryStr2font(className, anwser) explanation = "" else: className = spans[0].attrs["class"][0] anwser = spans[0].text anwser = anwser.encode('raw_unicode_escape').decode('utf-8').replace('\\u', '') anwser = jerryStr2font(className, anwser) explanation = spans[1].text explanationCodes = ctx.call("decode", explanation) explanation = jerryStr2font(className, explanationCodes) print("【参考答案】:", anwser) print("【试题解析】:", explanation) o = '''{}\t{}\t{}\t{}\t{}\n'''.format(title, title2, selects, anwser, re.sub('"|\'', '', explanation)) outfile.write(o) #sheet.append([title, title2, selects, anwser, explanation]) # 插入一行数据 time.sleep(3*random.random()) #wb.save("part1.xlsx") outfile.close() ```
laihui126
2023年2月6日 09:09
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



