AI
基于paddlehub和wechaty实现一句话给你emoji过来【需添加实战】
paddleOCR--提取图片或PDF表格内容
sentence-transformers的使用
语音转文字-Whisper
pytorch版本对应问题
moviepy和scenedetect的用法
本地搭建AI大模型
DeepSeek使用技巧
DeepSeek实战
DeepSeek部署
DeepSeek R1打造个人知识库
DeepSeek+即梦
OpenManus本地部署
无限使用Cursor
cursor账号list
Crusor Pro Trial 试用账号个人白嫖 2025-07-26
谷歌Gemini-pro的使用
龙虾openclaw安装实践
本文档使用 MrDoc 发布
-
+
up
down
首页
语音转文字-Whisper
关于**语音识别**,这篇总结的很好:https://zhuanlan.zhihu.com/p/631859999 介绍下Whisper,这是一款离线的语音识别工具。 OpeanAI 推出的 Whipser 语音识别模型,绝对是目前最好的选择,没有之一。 对,它和 ChatGPT 是同门师兄弟。 ## Whisper Whipser 多语言语音识别模型,通过了 68 万小时的语音数据训练,支持 99 种语言,对英文的表现更是强无敌。 更重要的是,它开源免费,在电脑上就能离线使用。 https://github.com/openai/whisper 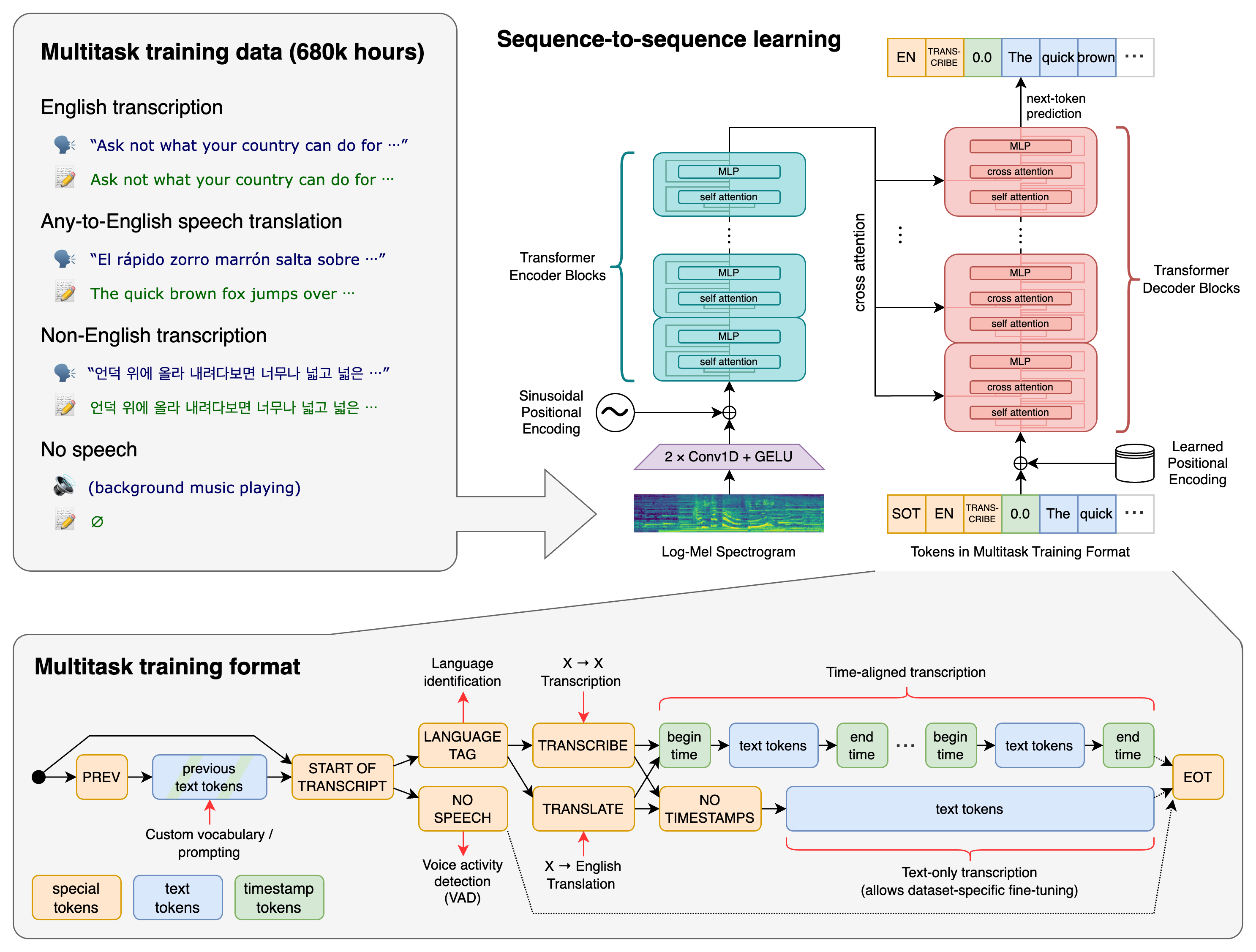 ### 安装方法 ``` pip install -U openai-whisper # 会自动安装一些依赖,如numpy、torch、tqdm、tiktoken等等 ``` 检查是否安装了ffmpeg,`ffmpeg`  测试whisper是否成功按照,`whisper`  ### 运行速度 为应对不同的语音转录需求,Whipser 推出了 tiny、base、small、medium、large 5 个档次的模型。 转录效果依次增加,但相应花费的时间也会增加。 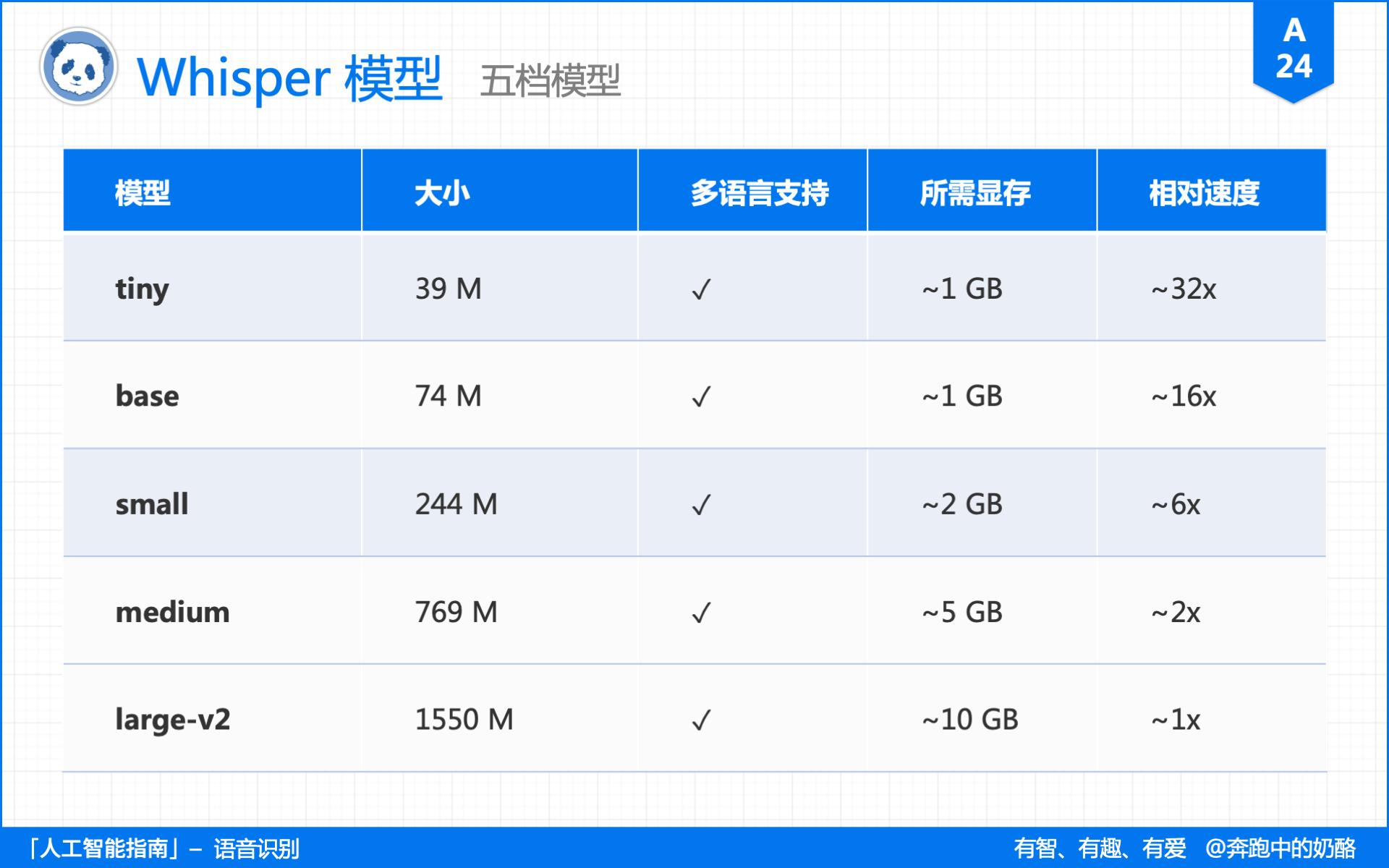 ### 使用方法 Whisper 使用了 Python 开发,安装后,在文件所在目录打开终端,运行 whisper audio.mp3 即可进行转录。 想要自定义设置的话,则可以在后面追加命令参数,具体包括: whisper audio.mp3 --命令参数  ``` --task 指定转录方式,默认使用 --task transcribe 转录模式,--task translate 则为翻译模式,目前只支持英文。 --model 指定使用模型,默认使用 --model small,Whisper 还有英文专用模型,就是在名称后加上 .en,这样速度更快。 --language 指定转录语言,默认会截取 30 秒来判断语种,但最好指定为某种语言,比如指定中文是 --language Chinese。 --device 指定硬件加速,默认使用 auto 自动选择,--device cuda 则为显卡,cpu 就是 CPU, mps 为苹果 M1 芯片。 ```
laihui126
2023年10月28日 13:34
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



