python经典学习
设置pip的国内镜像下载源
python经典项目必学或必会用【持续更新。。。】
python使用虚拟环境virtualenv
如何正确移除selenium中的window.navigator.webdriver
PyAutoGUI-python版按键精灵
QT中使用QSS进行界面美化及很好的QSS样式表
【AI】使用Stable Diffusion的WebUi版本
Mojo新语言的学习
使用Nuitka打包exe程序
python常见错误
超强的python库--vaex
python库-zmail的使用
python库-APScheduler定时任务
rich库--终端显示美化神器
关于套用lut的库使用-pycubelut和lutlib
本文档使用 MrDoc 发布
-
+
up
down
首页
python库-APScheduler定时任务
Python中定时任务的解决方案,总体来说有四种,分别是:crontab、 scheduler、 Celery、 APScheduler,其中 crontab不适合多台服务器的配置、scheduler太过于简单、 Celery依赖的软件比较多,比较耗资源。最好的解决方案就是 APScheduler。 APScheduler使用起来十分方便。提供了基于日期、固定时间间隔以及 crontab类型的任务。还可以在程序运行过程中动态的新增任务和删除任务。在任务运行过程中,还可以把任务存储起来,下次启动运行依然保留之前的状态。另外最重要的一个特点是,因为他是基于 Python语言的库,所以是可以跨平台的,一段代码,处处运行! ## 安装 `pip install apscheduler` ## 使用方法 ### 示例 ``` >>> import datetime >>> from datetime import datetime >>> from apscheduler.schedulers.blocking import BlockingScheduler >>> def job1(): ... print("Hello! now time is:%s"%datetime.now()) ... >>> scheduler = BlockingScheduler() >>> scheduler.add_job(job1, "interval", seconds=5) <Job (id=83094d050d8f476b8e362878de4ab9fe name=job1)> >>> scheduler.start() Hello! now time is:2023-12-20 14:09:22.112973 Hello! now time is:2023-12-20 14:09:27.113912 Hello! now time is:2023-12-20 14:09:32.113658 Hello! now time is:2023-12-20 14:09:37.113677 Hello! now time is:2023-12-20 14:09:42.113668 Hello! now time is:2023-12-20 14:09:47.113660 Hello! now time is:2023-12-20 14:09:52.113617 Hello! now time is:2023-12-20 14:09:57.113607 Hello! now time is:2023-12-20 14:10:02.113630 ... ``` 程序定义了一个job1函数,这个函数就是需要定时调度的任务代码。 BlockingScheduler是**阻塞性的调度器,是最基本的调度器**,下面**调用 start方法就会阻塞当前进程**,所以如果你的程序除了调度进程没有其他后台进程,那么是可以的,否则这个调度器会阻塞你程序的正常执行。 实例化一个 BlockingScheduler对象,并把 job1 添加到任务调度中。然后看 `interval`参数,这里用的是间隔的方式来调度,调度频率是`seconds=5`,也就是每5秒执行一次。 ## APScheduler的四个基本对象 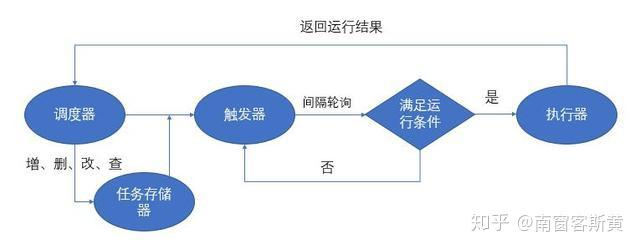 ### 1. 触发器(triggers): 触发器就是根据你指定的触发方式,比如是按照时间间隔interval,还是按照 crontab触发,触发条件是什么等。每个任务都有自己的触发器。有3种触发器: - [date触发器](https://apscheduler.readthedocs.io/en/stable/modules/triggers/date.html),在某个日期时间只触发一次事件。示例代码如下: ``` from datetime import date from apscheduler.schedulers.blocking import BlockingScheduler sched = BlockingScheduler() def my_job(text): print(text) # The job will be executed on November 6th, 2023 sched.add_job(my_job, 'date', run_date=date(2023, 11, 6), args=['text']) sched.start() ``` 也可以是精确时间: `sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5), args=['text'])` 或者,运行日期可以是文本: `sched.add_job(my_job, 'date', run_date='2009-11-06 16:30:05', args=['text'])` 或者,立刻执行: `sched.add_job(my_job, args=['text'])` - [interval触发器](https://apscheduler.readthedocs.io/en/stable/modules/triggers/interval.html),允许在固定的时间间隔触发事件。interval的触发器可以设置以下的触发参数: ``` weeks:周。(int) days:一个月中的第几天。(int) hours:小时。(int) minutes:分钟。(int) seconds:秒。(int) start_date:间隔触发的起始时间。 end_date:间隔触发的结束时间。 jitter:触发的时间误差(秒) ``` (每间隔2小时触发事件)示例: ``` from datetime import datetime from apscheduler.schedulers.blocking import BlockingScheduler def job_function(): print("Hello World") sched = BlockingScheduler() # Schedule job_function to be called every two hours sched.add_job(job_function, 'interval', hours=2) sched.start() ``` 可以使用start_date和end_date来限制任务总时间: ``` # The same as before, but starts on 2010-10-10 at 9:30 and stops on 2014-06-15 at 11:00 sched.add_job(job_function, 'interval', hours=2, start_date='2010-10-10 09:30:00', end_date='2014-06-15 11:00:00') ``` - [rontab触发器](https://apscheduler.readthedocs.io/en/stable/modules/triggers/cron.html) 在某个确切的时间周期性的触发事件。可以使用的参数如下: ``` year:4位数字的年份。 month:1-12月份。 day:1-31日。 week:1-53周。 day_of_week:一个礼拜中的第几天( 0-6或者 mon、 tue、 wed、 thu、 fri、 sat、 sun)。 hour: 0-23小时。 minute: 0-59分钟。 second: 0-59秒。 start_date: datetime类型或者字符串类型,起始时间。 end_date: datetime类型或者字符串类型,结束时间。 timezone:时区。 jitter:任务触发的误差时间。 ``` 也可以用表达式类型,可以用以下方式: 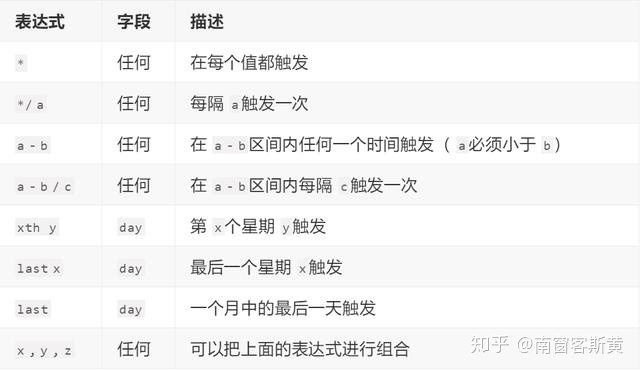 ``` from apscheduler.schedulers.blocking import BlockingScheduler def job_function(): print "Hello World" sched = BlockingScheduler() # Schedules job_function to be run on the third Friday # of June, July, August, November and December at 00:00, 01:00, 02:00 and 03:00 sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3') sched.start() ``` 在6-8、11-12每个月中的第3个周五0、1、2、3点执行。 可以使用start_date和end_date来限制任务总时间: ``` # Runs from Monday to Friday at 5:30 (am) until 2014-05-30 00:00:00 sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2024-05-30') ``` 也可以使用装饰器: ``` @sched.scheduled_job('cron', id='my_job_id', day='last sun') def some_decorated_task(): print("I am printed at 00:00:00 on the last Sunday of every month!") ``` ### 2. 任务存储器(job stores): 任务存储器是可以存储任务的地方,默认情况下任务保存在内存,也可将任务保存在各种数据库中。任务存储进去后,会进行序列化,然后也可以反序列化提取出来,继续执行。 一是内存,也是默认的配置。二是数据库。使用**内存的方式是简单高效**,但是不好的是,一旦程序出现问题,重新运行的话,会把之前已经执行了的任务重新执行一遍。**数据库则可以在程序崩溃后,重新运行可以从之前中断的地方恢复正常运行**。有以下几种选择: 1. MemoryJobStore:没有序列化,任务存储在内存中,增删改查都是在内存中完成。 2. SQLAlchemyJobStore:使用 SQLAlchemy这个 ORM框架作为存储方式。 3. MongoDBJobStore:使用 mongodb作为存储器。 4. RedisJobStore:使用 redis作为存储器。 ### 3. 执行器(executors): 执行器的目的是安排任务到线程池或者进程池中运行的。执行器的选择取决于应用场景。通常默认的 ThreadPoolExecutor已经在大部分情况下是可以满足我们需求的。如果我们的任务涉及到一些 CPU密集计算的操作。那么应该考虑 ProcessPoolExecutor。然后针对每种程序,apscheduler也设置了不同的 executor: 1. ThreadPoolExecutor:线程池执行器。 2. ProcessPoolExecutor:进程池执行器。 3. GeventExecutor: Gevent程序执行器。 4. TornadoExecutor: Tornado程序执行器。 5. TwistedExecutor: Twisted程序执行器。 6. AsyncIOExecutor: asyncio程序执行器。 ### 4. 调度器(schedulers): 任务调度器是属于整个调度的总指挥官。他会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。开发人员很少直接操作触发器、存储器、执行器等。因为这些都由调度器自动来实现了。 1. BlockingScheduler:适用于调度程序是进程中唯一运行的进程,调用 start函数会阻塞当前线程,不能立即返回。 2. BackgroundScheduler:适用于调度程序在应用程序的后台运行,调用 start后主线程不会阻塞。 3. AsyncIOScheduler:适用于使用了 asyncio模块的应用程序。 4. GeventScheduler:适用于使用 gevent模块的应用程序。 5. TwistedScheduler:适用于构建 Twisted的应用程序。 6. QtScheduler:适用于构建 Qt的应用程序。 ## 定时任务调度配置: 这里我们用一个例子来说明。比如我想这样配置 执行器: 配置 default执行器为 ThreadPoolExecutor,并且设置最多的线程数是20个。 存储器: 配置 default的任务存储器为 SQLAlchemyJobStore(使用SQLite)。 任务配置: 设置 coalesce为 False:设置这个目的是,比如由于某个原因导致某个任务积攒了很多次没有执行(比如有一个任务是1分钟跑一次,但是系统原因断了5分钟),如果 coalesce=True,那么下次恢复运行的时候,会只执行一次,而如果设置 coalesce=False,那么就不会合并,会5次全部执行。 max_instances=5:同一个任务同一时间最多只能有5个实例在运行。比如一个耗时10分钟的job,被指定每分钟运行1次,如果我 max_instance值5,那么在第6~10分钟上,新的运行实例不会被执行,因为已经有5个实例在跑了。 那么代码如下:   ## 任务操作: 1. 添加任务: 使用 `scheduler.add_job(job_obj,args,id,trigger,**trigger_kwargs)`。 2. 删除任务: 使用 `scheduler.remove_job(job_id,jobstore=None)`。 3. 暂停任务: 使用 `scheduler.pause_job(job_id,jobstore=None)`。 4. 恢复任务: 使用 `scheduler.resume_job(job_id,jobstore=None)`。 5. 修改某个任务属性信息: 使用 `scheduler.modify_job(job_id,jobstore=None,**changes)`。 6. 修改单个作业的触发器并更新下次运行时间: 使用 `scheduler.reschedule_job(job_id,jobstore=None,trigger=None,**trigger_args)` 7. 输出作业信息: 使用 `scheduler.print_jobs(jobstore=None,out=sys.stdout)` ## 异常监听: 当我们的任务抛出异常后,我们可以监听到,然后把错误信息进行记录。示例代码如下: ``` from apscheduler.schedulers.blocking import BlockingScheduler from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR import datetime import logging # 配置日志显示 ```   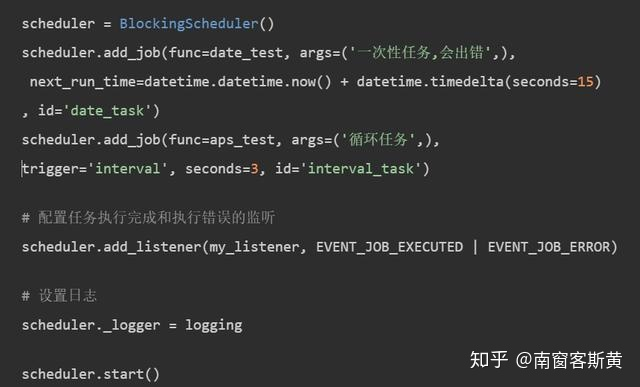
laihui126
2023年12月26日 14:31
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



