python经典学习
设置pip的国内镜像下载源
python经典项目必学或必会用【持续更新。。。】
python使用虚拟环境virtualenv
如何正确移除selenium中的window.navigator.webdriver
PyAutoGUI-python版按键精灵
QT中使用QSS进行界面美化及很好的QSS样式表
【AI】使用Stable Diffusion的WebUi版本
Mojo新语言的学习
使用Nuitka打包exe程序
python常见错误
超强的python库--vaex
python库-zmail的使用
python库-APScheduler定时任务
rich库--终端显示美化神器
关于套用lut的库使用-pycubelut和lutlib
本文档使用 MrDoc 发布
-
+
up
down
首页
超强的python库--vaex
[vaex的GitHub地址](https://github.com/vaexio/vaex) vaex 是一个用于**处理和分析大型数据集的高性能的 Python 库**,**能够每秒处理数亿甚至数十亿行,而无需将整个数据集加载到内存中**。这使得它对于超出单台机器可用 RAM 的大型数据集的探索、可视化和统计分析特别有用。 ## 特点 - 内存效率:Vaex 可以通过使用磁盘内存映射和延迟加载来处理太大而无法放入内存的大型数据集。这使得 Vaex 成为处理数据集的绝佳工具,否则需要分布式计算系统。 - 快速:Vaex 的设计速度快、效率高,非常适合处理大型数据集。它使用惰性求值来最大限度地减少对数据执行操作所需的计算量,并且支持并行处理以充分利用多核 CPU。 - 简单的语法:Vaex 具有简单直观的语法,可以轻松处理大型数据集。它的 API 与 Pandas 类似,因此如果你已经熟悉 Pandas,你会发现 Vaex 很容易学习。 - 内置可视化:Vaex 具有内置可视化功能,因此你可以快速创建绘图和图表来可视化数据。 - 跨平台兼容性:Vaex 设计为在多个平台上工作,可在 Windows、Linux 和 macOS 上使用。 ## 安装 `pip install vaex` 安装了vaex-4.1.0版,需要等待一会,会有许多依赖包需要安装: `aplus-0.11.0 astropy-4.3.1 backcall-0.2.0 blake3-0.3.3 bqplot-0.12.42 branca-0.7.0 comm-0.1.4 frozendict-2.3.10 httptools-0.2.0 ipydatawidgets-4.3.5 ipyleaflet-0.18.0 ipympl-0.9.3 ipython-7.34.0 ipyvolume-0.6.3 ipyvue-1.10.1 ipyvuetify-1.8.10 ipywebrtc-0.6.0 ipywidgets-8.1.1 jedi-0.19.1 jupyterlab-widgets-3.0.9 llvmlite-0.39.1 matplotlib-inline-0.1.6 nest-asyncio-1.5.8 numba-0.56.4 parso-0.8.3 pexpect-4.9.0 pickleshare-0.7.5 progressbar2-4.2.0 ptyprocess-0.7.0 pyarrow-12.0.1 pyerfa-2.0.0.3 python-dotenv-0.21.1 python-utils-3.5.2 pythreejs-2.4.2 tornado-6.2 traittypes-0.2.1 uvloop-0.18.0 vaex-4.17.0 vaex-astro-0.9.3 vaex-core-4.17.1 vaex-hdf5-0.14.1 vaex-jupyter-0.8.2 vaex-ml-0.18.3 vaex-server-0.9.0 vaex-viz-0.5.4 watchgod-0.8.2 widgetsnbextension-4.0.9 xarray-0.20.2 xyzservices-2023.2.0` ## 测试 创建虚拟数据集,100w行,51列的数据集,保存到data.csv ``` import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(0, 100, size=(10000000, 50))) df = df.rename(columns={i:f"x_{i} " for i in range(50)}) df["category"] = ["A", "B", "C", "D"] * 2500000 df.to_csv('data.csv') ``` 读取数据速度 ``` import vaex vdf = vaex.read_csv("data.csv") df = pd.read_csv("data.csv") ``` 案例一:选择属于类别 A 的行来执行过滤操作。 ``` %time df_a = df[df["category"]=="A"] %time vdf_a = vdf[vdf["category"] =="A"] ``` 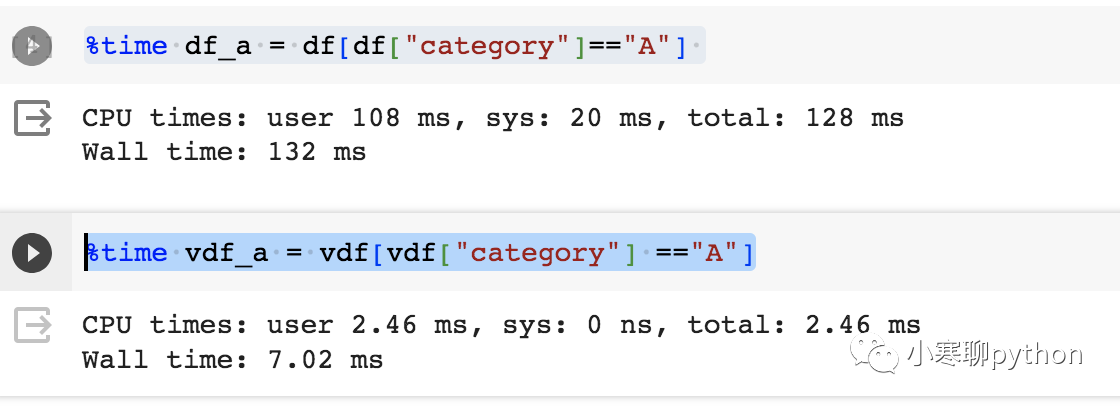 **pandas 用时 132 ms,而 Vaex 只需要 7.02 ms。** 案例二:对df进行排序。 ``` %time df_sorted = df.sort_values(by="x_1 ",ascending=False,axis=0) %time vdf_sorted = vdf.sort(by=["x_1 "], ascending=["False"]) ``` 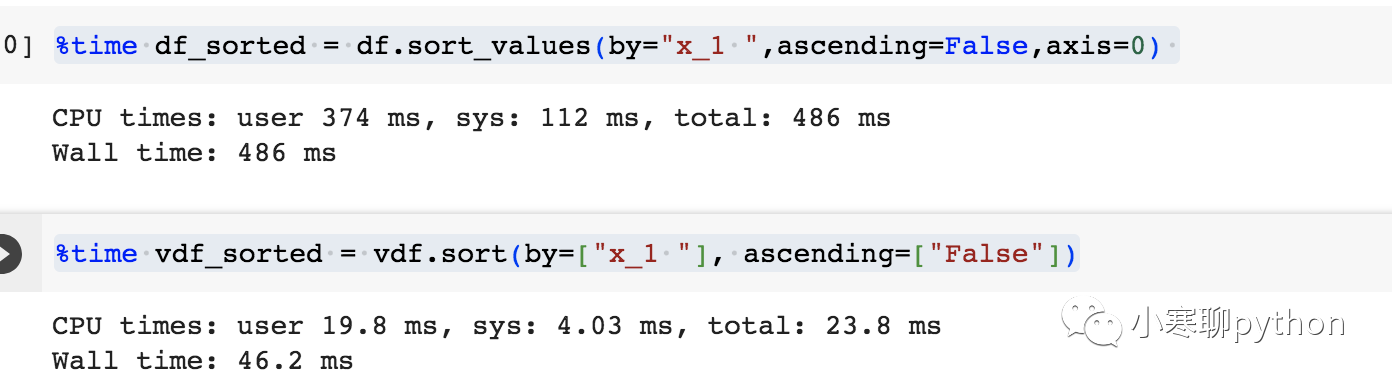 **pandas 用时 486 ms,而 Vaex 只需要 46.2 ms。** 案例三:按两列对行进行排序。 ``` %time df_sorted = df.sort_values(by=["x_1 ", "x_2 "], ascending=[False, True]) %time vdf_sorted = vdf.sort(by=["x_1 ", "x_2 "], ascending=["False", "True"]) ``` 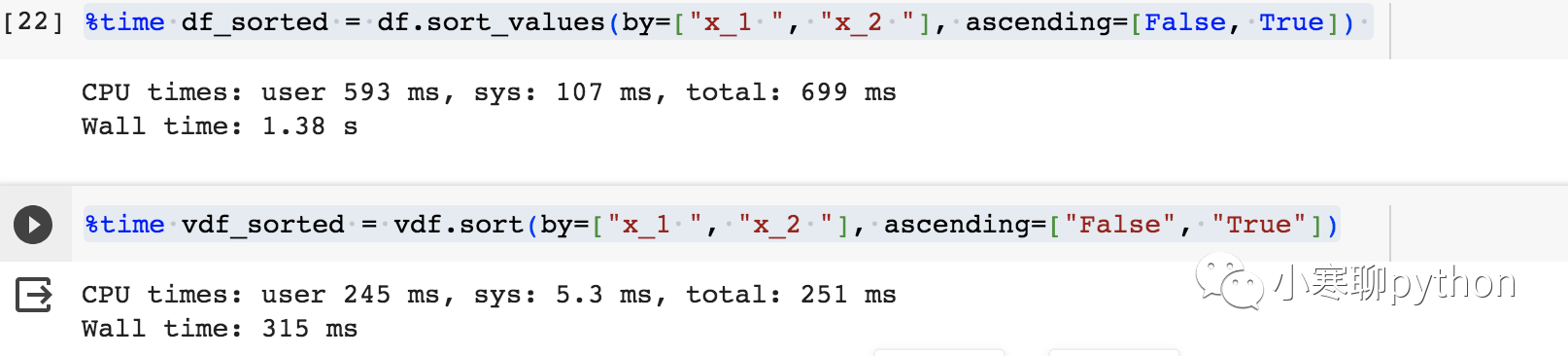 **pandas 用时 1.38 s,而 Vaex 只需要 315 ms。** 案例四:使用其他列创建新列 ``` %time df["new"] = df["x_1 "]**2 + df["x_2 "]**2 %time vdf["new"] = vdf["x_1 "]**2 + vdf["x_2 "]**2 ```  **pandas 用时 11.1 ms,而 Vaex 只需要 1.76 ms。**
laihui126
2023年12月5日 15:05
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



