python经典学习
设置pip的国内镜像下载源
python经典项目必学或必会用【持续更新。。。】
python使用虚拟环境virtualenv
如何正确移除selenium中的window.navigator.webdriver
PyAutoGUI-python版按键精灵
QT中使用QSS进行界面美化及很好的QSS样式表
【AI】使用Stable Diffusion的WebUi版本
Mojo新语言的学习
使用Nuitka打包exe程序
python常见错误
超强的python库--vaex
python库-zmail的使用
python库-APScheduler定时任务
rich库--终端显示美化神器
关于套用lut的库使用-pycubelut和lutlib
本文档使用 MrDoc 发布
-
+
up
down
首页
python常见错误
## 编码错误 遇到编码错误: `UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 4364: illegal multibyte sequence` 通常解决方案: ### 指定正确的编码格式 **先排除编码格式**,大部分都是这个问题,如使用 `with open('file.txt', 'rt', encoding='utf-8') as f` 如UPD分析时,用到PyVCF3模块,该模块在构建reader类的时候,是具备encoding参数的,在我们构造的模块ReadVCFs2dict.py中,加入 ``` import vcf vcf_reader = vcf.Reader(filename = vcfn, strict_whitespace=True, encoding="utf-8") ``` 但是仍然报错,根据错误内容: 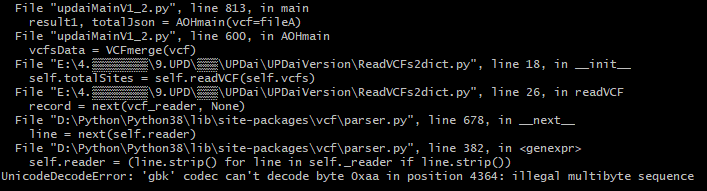 于是,对该模块具体查看, 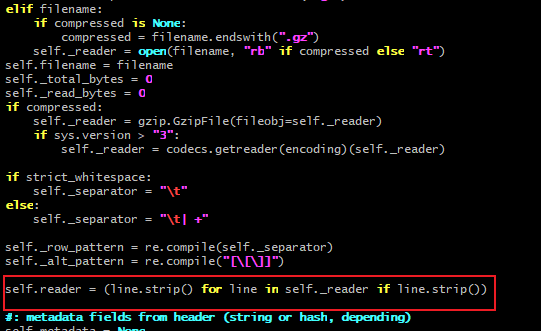 红框里这一句报错,主要是self._reader 在构建的时候里面没有指定编码:`self._reader = open(filename, "rb" if compressed else "rt")`,改为下面即可不会报错了,encoding的值是外界传入的,如"utf-8" `self._reader = open(filename, "rb" if compressed else "rt", encoding=encoding)` ### 使用适当的错误处理方法 在某些情况下,我们可能无法确定文件的实际编码格式,或者无法更改代码以指定正确的编码格式。在这种情况下,可以使用适当的错误处理方法来处理UnicodeDecodeError错误。 一种常见的错误处理方法是使用errors参数。errors参数可以接受不同的值,用于指定在解码过程中遇到错误时的处理方式。常用的值包括: - ignore:忽略错误,跳过无法解码的字符。 - replace:用特定字符(例如问号)替换无法解码的字符。 - strict:默认值,遇到错误时引发UnicodeDecodeError异常。 例如,代码如下: `with open('file.txt', errors='ignore') as f:` ### 尝试不同的编码格式 以上方法都无法解决问题,我们可以尝试使用不同的编码格式来解码文件。可以使用chardet库来自动检测文件的实际编码格式。该库可以根据文件的内容推断出最可能的编码格式。 首先,确保已经安装了chardet库: `pip install chardet` ``` import chardet def get_file_encoding(file_path): with open(file_path, 'rb') as f: result = chardet.detect(f.read()) return result['encoding'] file_path = 'file.txt' encoding = get_file_encoding(file_path) with open(file_path, encoding=encoding) as f: # 处理文件内容 ```
laihui126
2023年11月22日 17:32
分享文档
收藏文档
上一篇
下一篇
微信扫一扫
复制链接
手机扫一扫进行分享
复制链接
关于 MrDoc
觅道文档MrDoc
是
州的先生
开发并开源的在线文档系统,其适合作为个人和小型团队的云笔记、文档和知识库管理工具。
如果觅道文档给你或你的团队带来了帮助,欢迎对作者进行一些打赏捐助,这将有力支持作者持续投入精力更新和维护觅道文档,感谢你的捐助!
>>>捐助鸣谢列表
微信
支付宝
QQ
PayPal
下载Markdown文件
分享
链接
类型
密码
更新密码



